Procesadores con emisión múltiple de instrucciones
Procesadores paralelos
- Procesadores de instrucciones largas (emisión estática): Lo decide el compilador. Cada instrucción codifica múltiples operaciones
- Procesadores superescalares (emisión dinámica): La CPU examina las instrucciones y elige las que mitir. La CPU resuelve los riesgos en tiempo de ejecución.
El paralelismo de una arquitectura se identifica con el número de instrucciones que se procesan a la vez.
$$ \text{Paralelismo} = \text{Velocidad} \cdot \text{Tiempo de ejecución} \\ P = r \cdot T $$
Procesadores de instrucciones largas (VLIW)
Very long instruction word: Emisión estática, detección de riesgos por SW, planificación estática, ejecución en orden, habituales en los DSP
- Empaqueta varias operaciones en cada instrucción. Se emiten en un mismo ciclo y se ejecutan concurrentemente. Determinadas por la arquitectura. Latencia fija
- Elimina los riesgos: reordena las instrucciones al empaquetarlas. Evita dependencias en el mismo paquete. Posibles riesgos por dependencias entre paquetes. Si es necesario añade
nop. Es decir, que no se usa.
MIPS con emisión estática dual
Paquetes con dos instrucciones (64 bits) -> Instrucción ALU/Branch + instrucción load/store
$$ IPC = \frac{\text{total inst.}}{\text{total ciclos}} $$
IPC (Número de instrucciones por ciclo)
Desenrrollado del bucle -> Más paralelismo, menos control.
Procesadores digitales de señal (DSP)
- Arquitectura VLIW
- ALU aritmética lógica (L)
- MAC multiplica/aculuma (M)
- Desplazador (S)
- Generador de direcciones (D)
- Detección de desbordamiento -> no utiliza truncado
- Formato de datos:
- Coma fija y coma flotante
- Suele usar palabras de 16 bits
- Procesador parido: paralelismo a nivel de datos
- Instrucciones específicas
- De repetición para bucles
- Especializadas para las UFs disponibles (VLIW)
- Acceso de datos:
- Amplio número de registros: acceso rápido a datos
- Bancos de memoria en paralelo
- Puede incorporar mecanismos para procesado vectorial
Ejecución en orden
Las instrucciones se escriben (WB) en orden.
Limitación: una instrucción larga (memoria) retrasa las siguientes
Emisión fuera de orden
Se almacenan múltiples instrucciones en un búfer de la etapa de emisión (estación de reserva) a la espera de ser emitidas.
Planificación dinámica:
- La etapa de decodificación va almacenando instrucciones que no causan riesgos por reuso de registros en un búfer a la espera de ser emitidas
- Toda instrucción en el búfer puede ser emitida una vez que los operandos y la unidad funcional están disponibles
- Antes de escribir en registro (WB) se regupera el orden en un búger de reordenación.
Renombrado de registros
Permite aumentar el número de registros que ofrece la ISA. Consigue eliminar los riesgos por reuso de registros. Solo quedan riesgos RAW que se ordenan estrictamente,
Ejecución especulativa
Paralelismo multihilo (Multithreading)
- Hilo: Secuencia de instrucciones. Comparte memoria con otros hilos del mismo proceso.
- Paralelismos multihilo
- Hilos independientes
- HW: replicar registros, PCs
- SW: Pthreads
- Grano fino (Fine MT): Cambio de hilo cada ciclo
- Grano grueso: Cambio con stalls largos. Simplifica el hardware
- Con emisión múltiple (SMT): Varios hilos en cada ciclo.
- Hilos independientes
CPU de ARM Cortex A8 (2005)
- Superescalar / estático
- Etapas IF(3), ID(5) y EX(6) -> Arquitectura 14 etapas
- Emisión dual en orden
- Predicción de saltos dinámica -> Fallo => 13 ciclos de penalización
$$ CPI_{ideal} = \frac{1}{\text{Instrucciones emitidas}} = \frac{1}{2} = 0.5 \\ CPI_{\text{real}} \text{ de 0.5 a 5 ciclos} $$
CPU de intel Core i7 (2008)
- Superescalar / dinámico
- Predicción de salto -> Penalización de 15 ciclos
- Carga de instrucción 16 bytes por ciclo
- Ejecución especulativa: Se llegan a descartar un 40%
$$ CPI_{ideal} = \frac{1}{\text{Instrucciones emitidas}} = \frac{1}{6} = 0.17 \\ CPI_{\text{real}} \text{ de 0.4 a 2.5 ciclos} $$
Sistemas paralelos a nivel de datos
Arquitecturas vectoriales
Funcionamiento básico:
- Carga los datos desde memoria a registros vectoriales.
- Streaming: flujo de datos desde registros UFs y a registros.
- Guarda los resultados desde los registros a memoria
Planificación estática por el compilador.
Ancho de banda de instruciones reducido.
Procesador vecorial VMIPS
Extensión vectorial de MIPS
- 8 regustros vectoriales de 64 elementos con 64 bits/elemento
- Unidades funcionales vectoriales
- Unidad load/store vectorial
- 32 registros escalares GP
- 32 registros escalares FP
Latencia en UFs
- Latencia inicial -> Llenado del pipeline
- Más de 1 elemento/ciclo
Bancos de memoria
- La memoria debe soportar el elevado ancho de banda
- Accesos distribuidos en multiples bancos de memoria. Cada banco mantiene un búfer de página distinto. Cada vector es un banco distinto, ampliable a varios procesadores con memoria compartida.
GPU
Unidades de procesamiento gráfico
- Se puede procesar flujos de datos (streams)
- Kernel: Programa que procesa flujos de datos
- Se asigna un hilo a cada elemento de datos
- Adaptación de aplicaciones
- Datos: Crear flujo de elementos paralelo.
- Descompone el problema en pequeños problemas (Kernels)
El paradígma de programación CUDA
Programa seria (Kernel) para un hilo (thread)
- Cada hilo se asocia a un elemento de datos -> pixel
- Los hilos se organizan en bloques -> blocks
- Los bloques se organizan en mallas-> grids
Invocación de un kernel
- kernel « gridDim< blockDim » (… parámetros ,,,)
- gridDim: número bloques por malla
- Número de hilos por bloque
Identificadores de hilos y bloques
- threadIdx.D identificador de hilo
- blockIdx.D identificador de bloque
Ejecución en CUDA
Ejecución:
- El HW de la GPU gestiona los hilos
- Hilos: en paralelo en distintas rutas de datos (lanes)
- Bloques: en procesadores SIMO (memoria compartida)
- Mallas: paralelo (independientes) o secuencia (dependientes)
Comunicaciones:
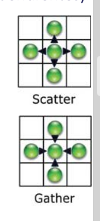
- Map: No hay comunicacones
- Scatter: se emite hacie direcciones (a[i] = x)
- Gather: se recibe desde direcciones (x = a[i])
Sincronización:
- Los hilos de un bloque usan barreras (barriers)
- Las mallas secuenciales tienen barreras implícitas
Evaluación de GPUs
- Simulitudes con arquitecturas vectoriales
- Diferencias con arquitecturas vectoriales
- No tienen procesador escalar
- Usan multithreading para ocultar la latencia de memoria
- Muchas más unidades funcionales
Multiprocesadores y redes de procesadores
Retos de la computación paralela
- Paralelismo limitado de las aplicaciones
- Alto coste de las comunicaciones
- Escalabilidad de las prestaciones
- Equilibrio de la carga en los procesadores
Escalabilidad lineal y coste-procesadores
- Al incrementar los procesadores, las prestaciones se incrementan en la misma medida
- No es necesario para mejorar la relación coste-procesadores
Programación de sistemas MIMD
- Descomposición (equilibrio carga vs. coste)
- Asignación a hilos o procesos (coste comunicaciones)
- Orquestación en un programa paralelo (sincronización)
- Mapeado a procesadores (localidad, topología)
Modelos de programación MIMD
- Memoria compartida: Espacio de memoria único, comunicaciones por memoria (load/store). Sincronización mediante cerrojos. Tiempo de acceso a memoria uniforme (UMA) o no uniforme (NUMA)
- Paso de mensajes:
- Nodos + red de interconexión.
- Nodo = Computador incluyendo E/S.
- Espacios de memoria privados por nodo comunicaciones por operaciones de E/S.
Coherencia de memoria
Todas las escrituyras se deben leer en orden correcto
- Memorias cache: Reducen el tráfico a memoria y la latencia. Generan el problema de la coherencia. Un dato puede ser leido y escrito en varios cachés a la vez.
Protocolos de coherencia:
- Cache coherente: añade bits de estado a cada dato.
- Esquemas vigia
- Esquemas con directorios
Mecanismos de sincronización
- Por exclusión mutua: cerrojos (locks)
- Problema: la operación lectura/escritura debe ser atómica
- Por evento: barreras, los procesos esperan a que todos llegen a la barrera
Paralelismo - ley de little
- Tasa(Throughput) : número total de unidades
- Tiempo de ejecución: \(\text{latencia media} = \frac{\text{nº unidades} \cdot \text{1 ciclo} + \text{nº unidades} \cdot \text{1 ciclo}}{\text{nº de unidades}}\)
- Paralelismo = Tasa x Tiemops de ejecución