Paralelismo y pipeline
Dos métricas comunes:
- Latencia (latency): tiempo en completar la tarea
- Rendimiento (throughput): Número de tareas completadas por unidad de tiempo
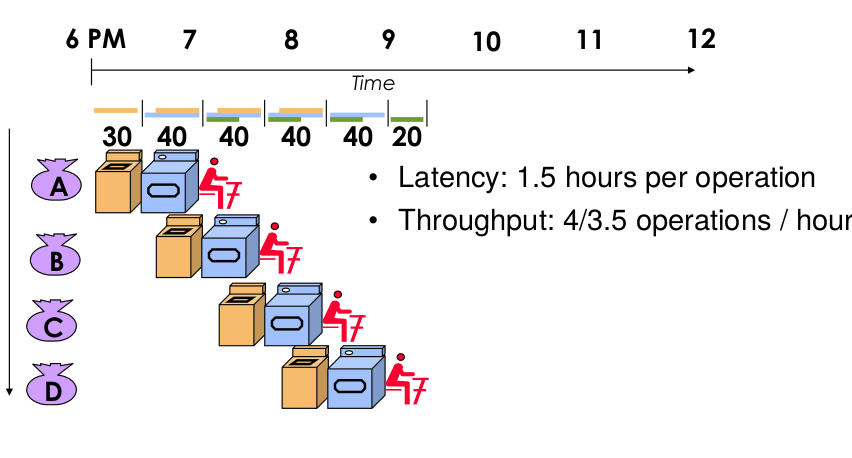
Estructura pipeline (tipo cola)
La latencia será la misma pero nuestro rendimiento cambiará. Tenemos varias tareas a la vez que usan recursos diferentes:
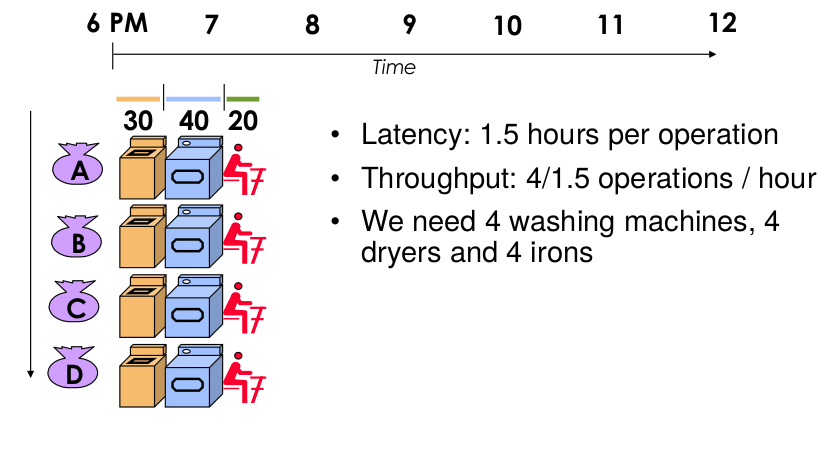
Estructura paralela
La latencia es la misma pero ahora multiplicamos recursos, es decir, tenemos varias tareas a la vez que usan el mismo tipo de recurso pero multiplicado.
Síntesis de alto nivel
Tiene como fin diseñar un algoritmo que tenga en cuenta en el hardware las restricciones de area, frecuencia, latencia, etc.
Data flow diagram muestra las dependencias entre los datos. Los nodos son operaciones, las flechas son variables.
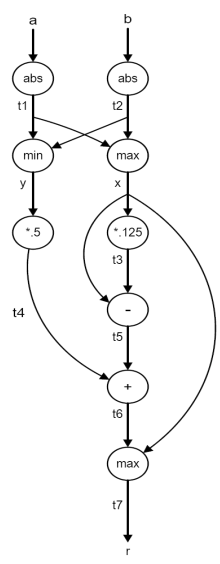
Metodología de síntesis de alto nivel
Allocation -> Asignación
Selección del número y tipo de unidades de hardware que vamos a utilizar. Podemos compartir operadores
Scheduling -> Lista del programa - orden temporal
Distribuimos las operaciones que tenemos en los diferentes ciclos, nunca excediendo el número de unidades de hardware que tenemos. Importante porque tiene impacto en nuestra latencia y rendimiento.
Binding -> Unión
Para cada etapa determinar cual de las unidades de hardware realiza la operación.
Implementación
Resulta en un datapath capaz de realizar el algoritmo para el que se diseñó.
- Estudio tiempo de vida de las varaibles -> registros
- Unión de los registros
- Asignación de multiplexores a cada operando
- Implementación hardware
Fixed point desing
Sin signo <a.b>
- a = número entero (bits)
- b = número fraccionario (bits)
- N = a+b
Con signo <s.a.b>
- s = signo
-
- b = número fraccionario (bits)
- N = 1+a+b
Suma
- <a.b> + <a.b> = <a+1.b>
- <s.a.b> + <s.a.b> = <s.a+1.b>
Multiplicación
- <a1.b1> x <a2.b2> = <a1+a2.b1+b2>
- <s.a1.b1> x <s.a2.b2> = <s.a1+a2.b1+b2> [Peor escenario]